
서버 컴퓨터를 부하테스트로 신나게 괴롭혀보자!
신설 서버 4대에 대한 부하테스트를 진행했습니다.
테스트 항목은 "최대성능"과 "안정성" 입니다.
최대성능 테스트 조건:
- 450명의 가상유저가 지속적으로 요청을 보내고, 응답 즉시 다시 요청을 보냄.
( 5 agents, 3 processes, 30 threads ) - 14명 가상유저 시작, 10초 간격으로 14명씩 추가
- 10분간 테스트
- 타켓 서버를 htop 명령어로 모니터링
- 2가지 요청 방식으로 각 1회 진행
안정성 테스트 조건:
- 25명의 가상유저가 지속적으로 요청을 보내고, 응답 즉시 다시 요청을 보냄.
- 25명의 가상유저 시작, 끝까지 유지
- 48시간 테스트
- 타켓 서버를 htop 명령어로 모니터링
- 기본 요청 방식으로 1회 진행
서버 구조:
| Agent Server | Agent Server | Agent Server | Agent Server | Agent Server |
▽ ▽ ▽
| Target Server | Target Server | Target Server | Target Server |
▽ ▽ ▽
| DataBase1, DataBase2 ... |
테스트 결과:
최대성능 테스트 - 기본 요청
해당 테스트는 가장 기초 테스트로, 1번DB와 한번 통신하는 테스트이다.
| TPS평균 / 최대 | 437.6 / 609 |
| 에러율 | 1.5% ( 3,884 / 260,654 ) |
| 평균 시행시간 | 660.59ms |
* TPS : Transaction Per Second 초당 거래량
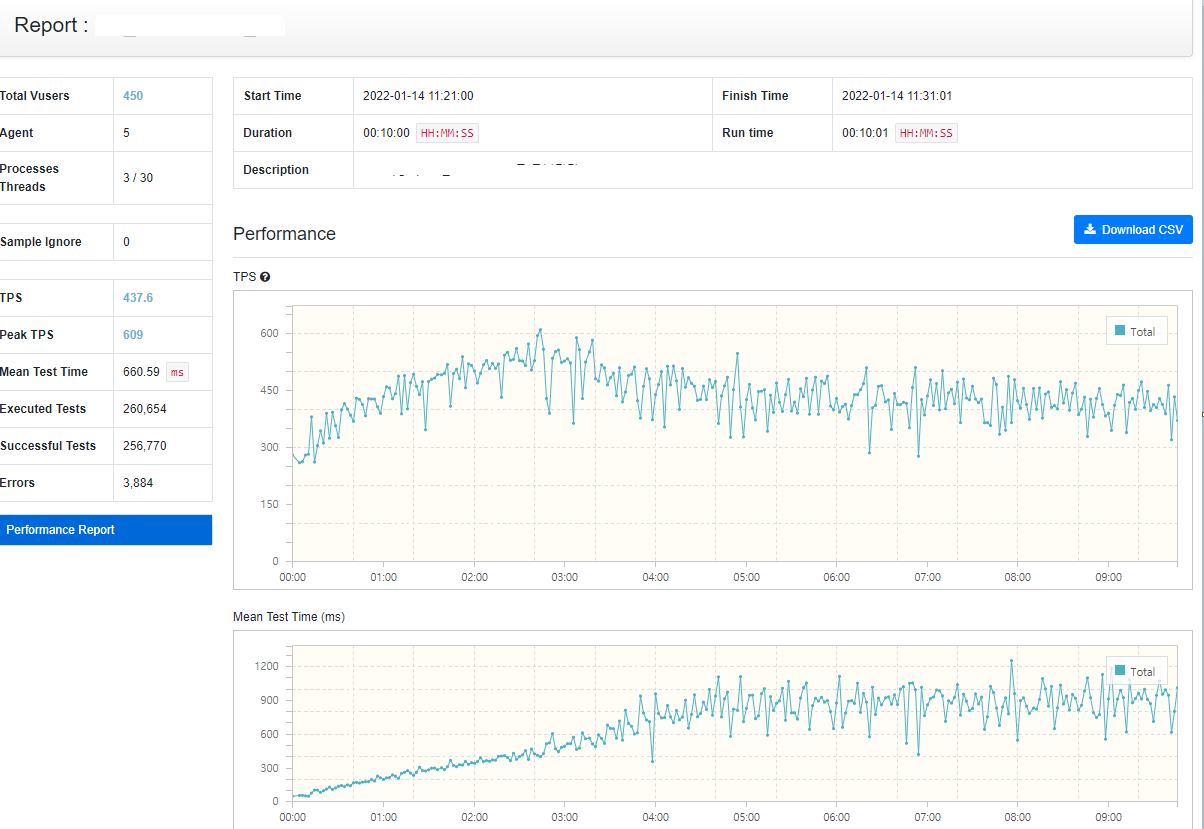

시작 5분은 괜찮았지만, 후반 5분에 많은 에러가 발생한 것을 볼 수 있다.
에러 발생 사유는 타임아웃 대기시간이 4초로 설정되어있기 때문이다.
실제 대기시간을 10초로 설정하고 재 테스트했더니 에러가 거의 사라졌다.
아래는 타겟 서버의 htop 모니터링 경과이다.

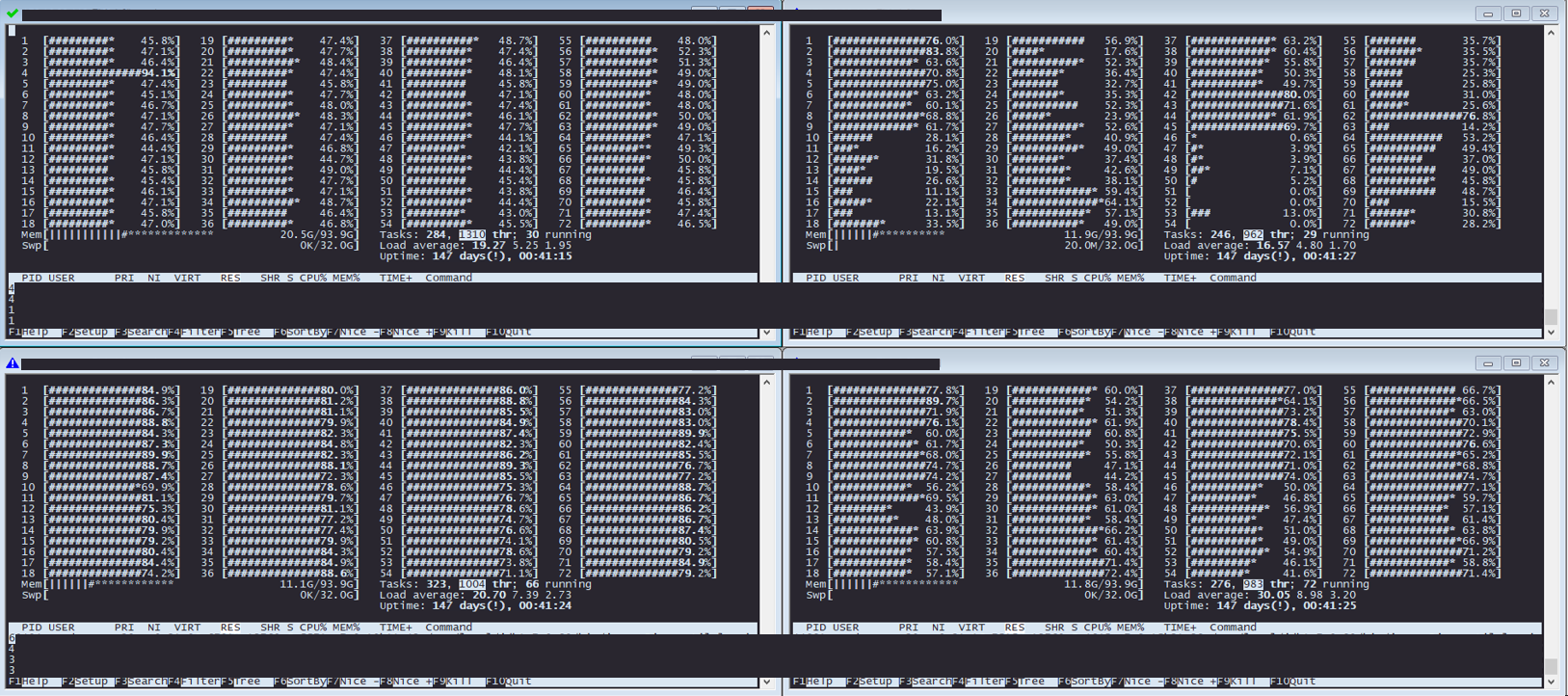
약 40명의 가상유저

약 70명의 가상유저

약 130명의 가상유저

약 200명의 가상유저

최대치인 420명의 가상유저. 이 이상 올라가지 않았다.
1대를 제외한 서버들이 폭삭 주저 앉은 순간을 캡쳐한 것이다.
CPU 사용량이 올라간 이유는 대부분 GC가 작동하기 때문이라고 한다.
하지만 GC 세팅 관련까지 들어가면 너무 깊게 들어가기 때문에...
일단 부하테스트는 마무리 짓고 다시 공부해보도록 하자.
아래는 scouter를 통해 모니터링한 결과, 이상한 점이 발견됐다.

XLog 를 보면 한번씩 팍 팍 튀는 현상이 보였다.
이 부분을 확인해보니, 해당 테스트에서 2번 DB와 통신하는 모습을 보였다(크흠...)
2번 DB는 실서비스에 사용중인 DB라 완전 Idle 한 1번 DB보다 트래픽이 많을 수 밖에 없다.
테스트 스크립트를 수정하여 1번 DB와만 통신하도록 했다.
다시 테스트한 결과


TPS 대폭향상, 가상유저 숫자도 450명까지 지정한 최대치로 올라갔으며

이렇게 크게 튀는 부분없이 일정하게 나오는 것이 정상적인 결과이다.
결론:
서버 컴퓨터의 CPU 자원이 부족한 모습을 보였다.
이는 절대적인 성능의 문제보다는, Tomcat 관련 설정을 통해 개선할 수 있을 것 같다.
Tomcat 이원화, nginx 와 같은 웹서버를 통한 로드벨런싱 등을 사용해볼 수 있다.
DB는 DB팀에 모니터링을 부탁한 결과 여유로웠다.
최대성능 테스트 - 다구간 통신 요청
해당 테스트는 1번 DB, 2번 DB 까지 통신하는 테스트이다.
| TPS평균 / 최대 | 154.5 / 250 |
| 에러율 | 10.9% ( 6,631 / 61,102 ) |
| 평균 시행시간 | 1372.01ms |
에러율이 높은 이유:
- 2번 DB는 실제 서비스가 운영중이다. Read Timeout 알람이 여러번 발생해, 6분 경과시 테스트를 중단했다.
- 타임아웃 시간이 기본 요청 테스트와 같이 4초로, 다소 짧아 부적절했다.

중간중간 서버가 힘들어서 주저 앉은 모습을 볼 수 있다.
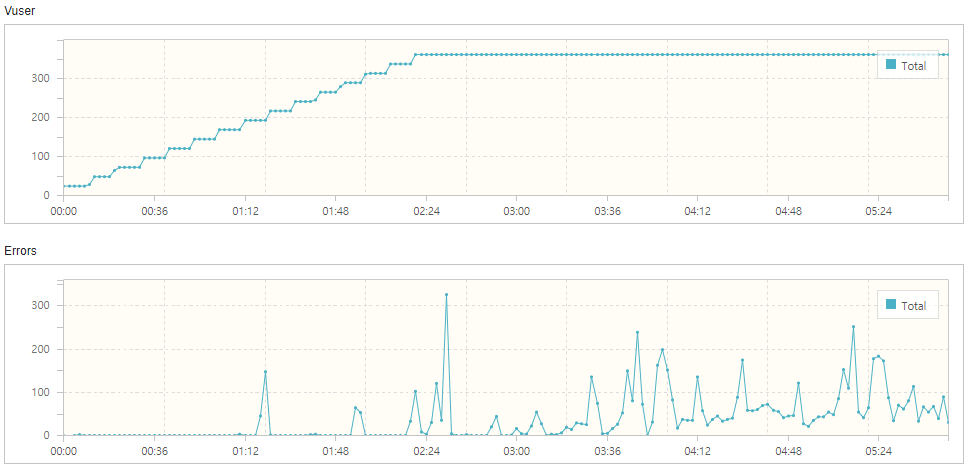
아래는 타겟서버의 htop 모니터링 경과이다.

100명의 가상유저

160명의 가상유저
250명의 가상유저

300명의 가상유저

360명의 가상유저. 최대치이며, 이 이상올라가지 않았다.

360명의 가상유저 테스트 중 잠깐 주저앉은 모습.
결론:
2번 DB가 실제 서비스 운영중인 서버라 정확한 테스트는 불가능했다.
그 이외는 전 테스트와 같은 결론이다.
안정성 테스트
해당 테스트는 1번 DB와 1회 통신을 48시간 지속실행한 테스트이다.
ngrinder 테스트 최대시간이 8시간이라, 6회 테스트를 예약하여 실행했다.


일정하게 24명의 가상유저를 유지하며 간간히 1~2회 타임아웃 에러가 발생했다.
결론:
1번 DB의 데이터 중 불필요한 데이터가 용량을 많이 차지함을 발견했다.
1번 DB는 마스터-슬레이브 구조를 가지는데, 해당 데이터를 마스터에만 저장하도록 수정했다.
최종결론:
성능개선을 원한다면 아래와 같은 조치를 취할 수 있겠다:
1. 2번 DB 성능 업그레이드
2. 서버 컴퓨터 소프트웨어를 통한 성능 개선 (톰캣 이원화, nginx와 같은 로드밸런싱 기능 SW 설치)
3. 서버 컴퓨터 하드웨어(CPU) 업그레이드. Scale Up, Scale Out 둘 다 선택 가능하다.
RAM 메모리는 상대적으로 여유로웠다. 하향 조정해도 괜찮다.
'개발 > Linux & DevOps' 카테고리의 다른 글
| docker jenkins CD/CI ② - publish over ssh 와 pipeline sshTransfer (0) | 2022.03.22 |
|---|---|
| docker jenkins CD/CI ① - 각자 역할, 작동 흐름 절차 (0) | 2022.03.21 |
| 부하 테스트 툴 ngrinder 3.5.5 구축&사용 후기! (0) | 2022.01.05 |
| Log4J 자바 보안 취약점, 버전 조회, 조치 방법 (0) | 2021.12.13 |
| [쌉꿀팁] 밋밋한 vim을 강력한 Vundle Vim 으로 파워업 시켜보자 (vimrc, nerdtree, vundlevim 설정) (0) | 2021.04.21 |



